Kubernetes Automated Cluster Scaling
AutoScaling is one of the most powerful concepts in Kubernetes.
This involves two main mechanisms:
- Horizontal Pod Autoscaling (HPA)
- Vertical Pod Autoscaling (VPA).
Automated cluster scaling refers to the process of dynamically adjusting the number of running pods (HPA) or their resource allocations (VPA) based on real-time metrics. This ensures that your applications can efficiently handle varying loads without manual intervention.
With HPA, you can scale smarter, and with VPA, scale wiser. HPA handles traffic spikes like a champ. VPA makes sure your pods get the resources they deserve.
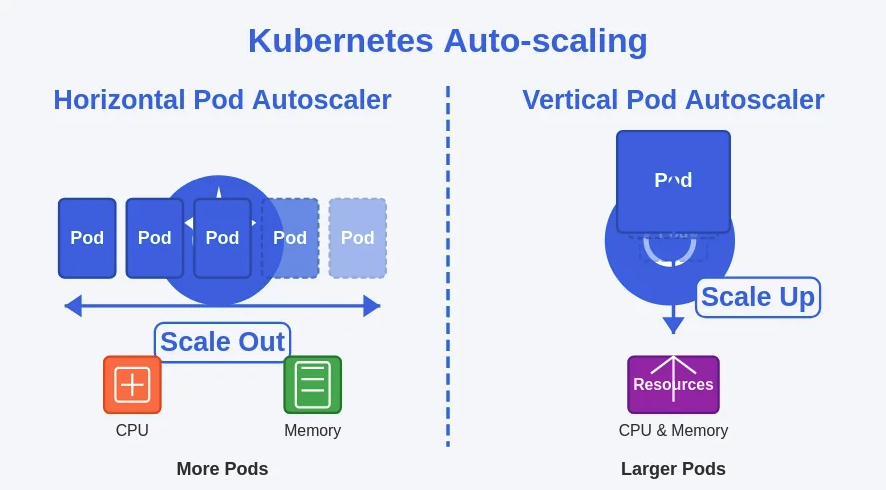
Horizontal Pod Autoscaling (HPA)
HPA automatically adjusts the number of pods in a deployment or replica set based on observed CPU utilization or other select metrics. For instance, if your application experiences a sudden increase in traffic, HPA will scale out by adding more pods to handle the load. Conversely, it will scale in by reducing the number of pods when the load decreases.
- Manual Scaling (Quick Recap). You manually scale pods using:
| |
Limitations: Manual, not reactive to load → not ideal for production.
Metrics Used: CPU/Memory utilization (via metrics-server).
Common Use Case: Web app getting heavy traffic → HPA increases pods → load balanced across more pods → better performance.
Key Fields in HPA YAML:
| |
| |
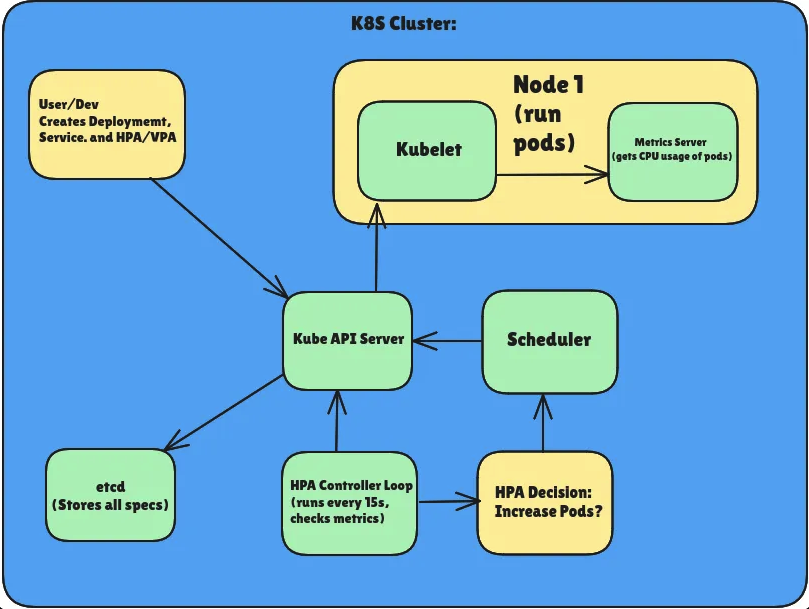
- Deploying the Metrics Server
Why: HPA needs CPU/memory stats → metrics-server collects and exposes these.
Install:
| |
- Create Pod + Service Example YAML:
| |
- Deploy the HPA
| |
- Simulate Load
To make CPU usage spike and trigger autoscaling:
| |
Inside the pod:
| |
This sends continuous traffic to the service, increasing CPU usage.
- Observe Scaling
| |
You’ll see replicas increasing as CPU crosses threshold (e.g., >50%).
| |
Eventually:
- More pods created
- CPU usage spread across them
- Load goes down
Vertical Pod Autoscaling (VPA)
VPA adjusts the resource requests and limits for your containers based on their usage. This means it can increase the CPU and memory allocated to a pod if it is consistently using more resources than initially requested, or it can reduce these allocations if the pod is over-provisioned.
What it does: Changes the resources (CPU, memory) allocated to each pod.
Use Case: Workloads where replica count doesn’t need to change, but need more resources.
Limitations: VPA restarts pods to apply changes.
Example YAML:
| |
Install the VPA components from their official GitHub if not available in your cluster.
Tolerance
version: Kubernetes v1.33
Tolerances appear under the spec.behavior.scaleDown and spec.behavior.scaleUp fields and can thus be different for scale up and scale down. A typical usage would be to specify a small tolerance on scale up (to react quickly to spikes), but higher on scale down (to avoid adding and removing replicas too quickly in response to small metric fluctuations).
| |